前言
1.模型整体思想
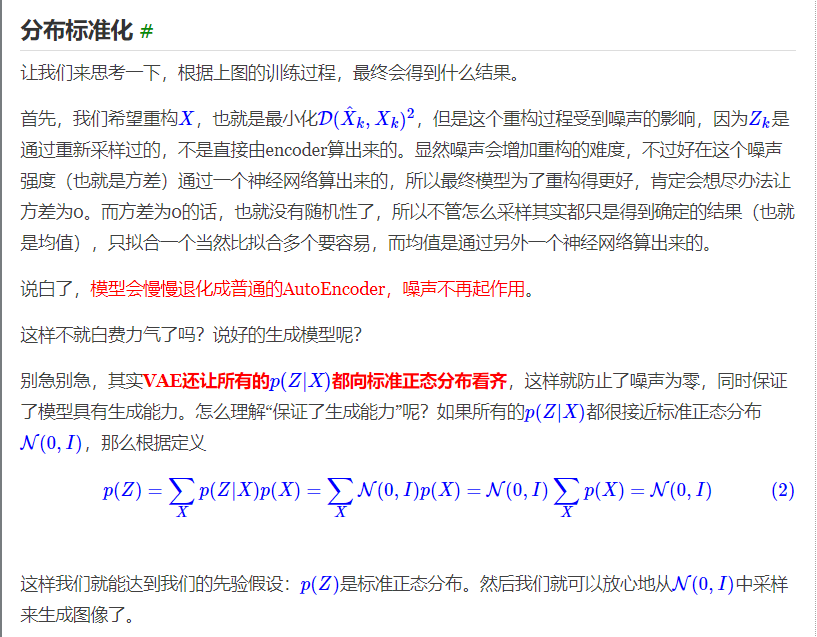
VAE本质上就是在我们常规的自编码器的基础上,对encoder的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,
使得结果decoder能够对噪声有鲁棒性;而那个额外的KL loss(目的是让均值为0,方差为1),
事实上就是相当于对encoder的一个正则项,希望encoder出来的东西均有零均值。
那另外一个encoder(对应着计算方差的网络)的作用呢?它是用来动态调节噪声的强度的。
直觉上来想,当decoder还没有训练好时(重构误差远大于KL loss),就会适当降低噪声(KL loss增加,
注意KL loss等于0表示分布就是标准正态分布),使得拟合起来容易一些(重构误差开始下降);
反之,如果decoder训练得还不错时(重构误差小于KL loss),这时候噪声就会增加(KL loss减少),
使得拟合更加困难了(重构误差又开始增加),这时候decoder就要想办法提高它的生成能力了。
说白了,重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的。
所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。


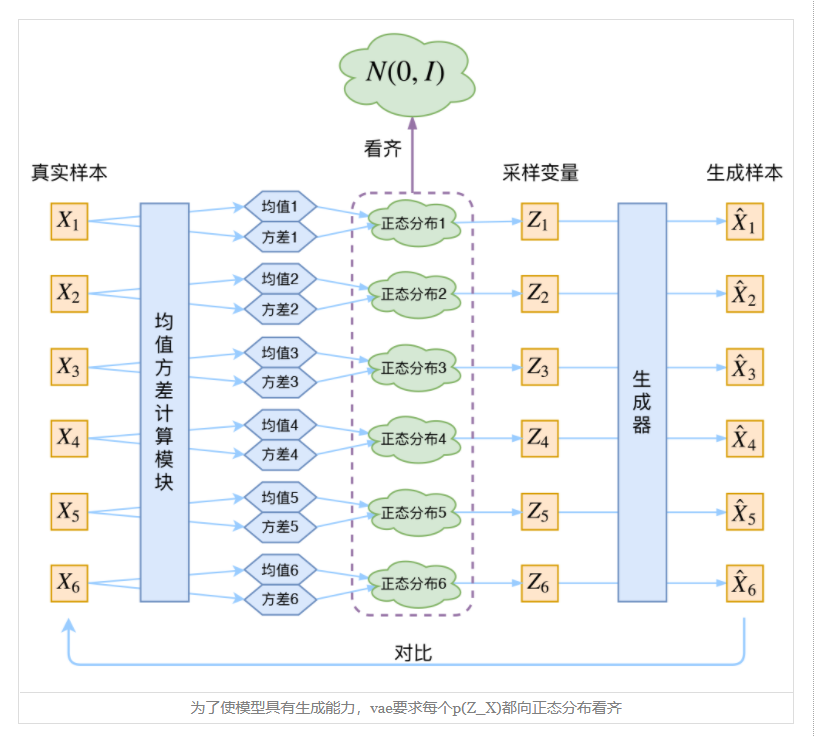


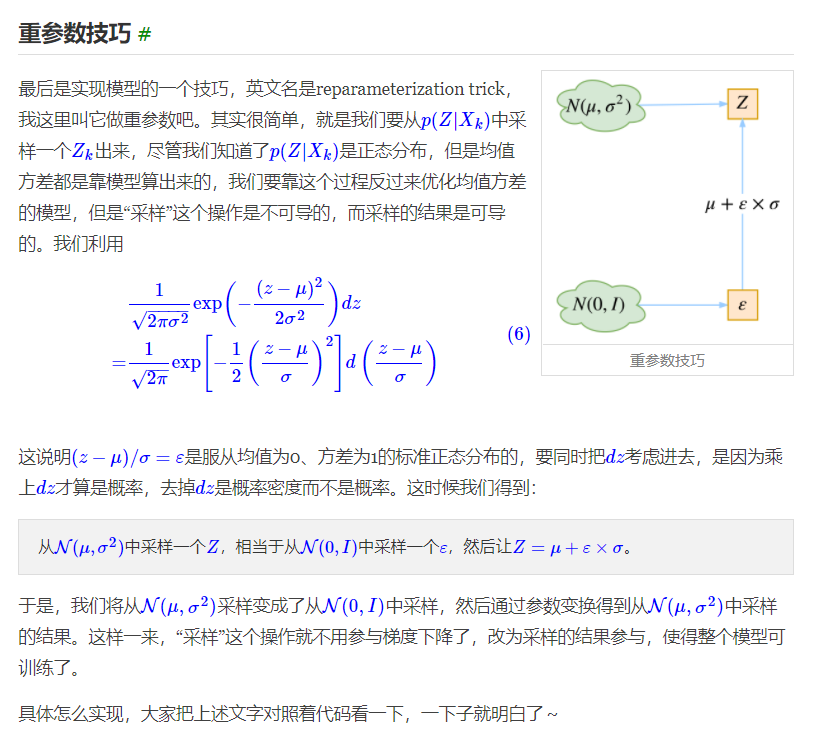

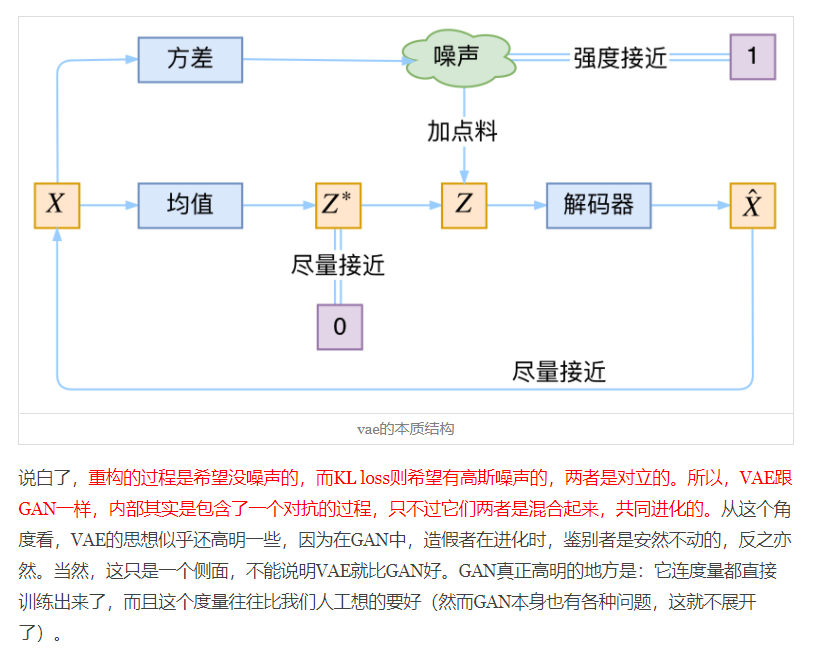


VAE源码
class Normal(object):
def __init__(self, mu, sigma, log_sigma, v=None, r=None):
self.mu = mu
self.sigma = sigma # either stdev diagonal itself, or stdev diagonal from decomposition
self.logsigma = log_sigma
dim = mu.get_shape()
if v is None:
v = torch.FloatTensor(*dim)
if r is None:
r = torch.FloatTensor(*dim)
self.v = v
self.r = r
class Encoder(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(Encoder, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
def forward(self, x):
x = F.relu(self.linear1(x))
return F.relu(self.linear2(x))
class Decoder(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(Decoder, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
def forward(self, x):
x = F.relu(self.linear1(x))
return F.relu(self.linear2(x))
class VAE(torch.nn.Module):
latent_dim = 8
def __init__(self, encoder, decoder):
super(VAE, self).__init__()
self.encoder = encoder
self.decoder = decoder
self._enc_mu = torch.nn.Linear(100, 8)
self._enc_log_sigma = torch.nn.Linear(100, 8)
def _sample_latent(self, h_enc):
"""
Return the latent normal sample z ~ N(mu, sigma^2)
"""
mu = self._enc_mu(h_enc)
log_sigma = self._enc_log_sigma(h_enc)
sigma = torch.exp(log_sigma)
std_z = torch.from_numpy(np.random.normal(0, 1, size=sigma.size())).float()
self.z_mean = mu
self.z_sigma = sigma
return mu + sigma * Variable(std_z, requires_grad=False) # Reparameterization trick
def forward(self, state):
h_enc = self.encoder(state)
z = self._sample_latent(h_enc)
return self.decoder(z)
#这部分是编码器生成与正态分布的差别,在loss中占一部分
def latent_loss(z_mean, z_stddev):
mean_sq = z_mean * z_mean
stddev_sq = z_stddev * z_stddev
return 0.5 * torch.mean(mean_sq + stddev_sq - torch.log(stddev_sq) - 1)
if __name__ == '__main__':
input_dim = 28 * 28
batch_size = 32
mnist = torchvision.datasets.MNIST('./', download=True )
dataloader = torch.utils.data.DataLoader(mnist, batch_size=batch_size,
shuffle=True, num_workers=2)
print('Number of samples: ', len(mnist))
encoder = Encoder(input_dim, 100, 100)
decoder = Decoder(8, 100, input_dim)
vae = VAE(encoder, decoder)
criterion = nn.MSELoss()
optimizer = optim.Adam(vae.parameters(), lr=0.0001)
l = None
for epoch in range(100):
for i, data in enumerate(dataloader, 0):
inputs, classes = data
inputs, classes = Variable(inputs.resize_(batch_size, input_dim)), Variable(classes)
optimizer.zero_grad()
dec = vae(inputs)
ll = latent_loss(vae.z_mean, vae.z_sigma)
#损失包含两部分,一部分是正太分布的损失,一部分是生成与预期的损失
loss = criterion(dec, inputs) + ll
loss.backward()
optimizer.step()
l = loss.data[0]
print(epoch, l)