前言
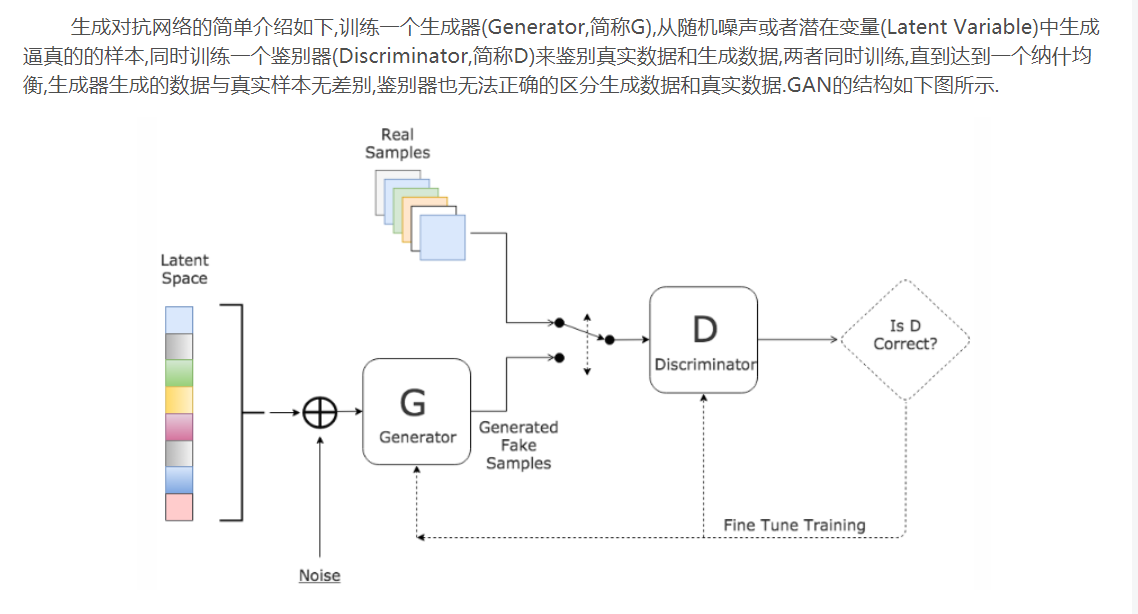
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,
是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:
生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。
但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,
否则可能由于神经网络模型的自由性而导致输出不理想。






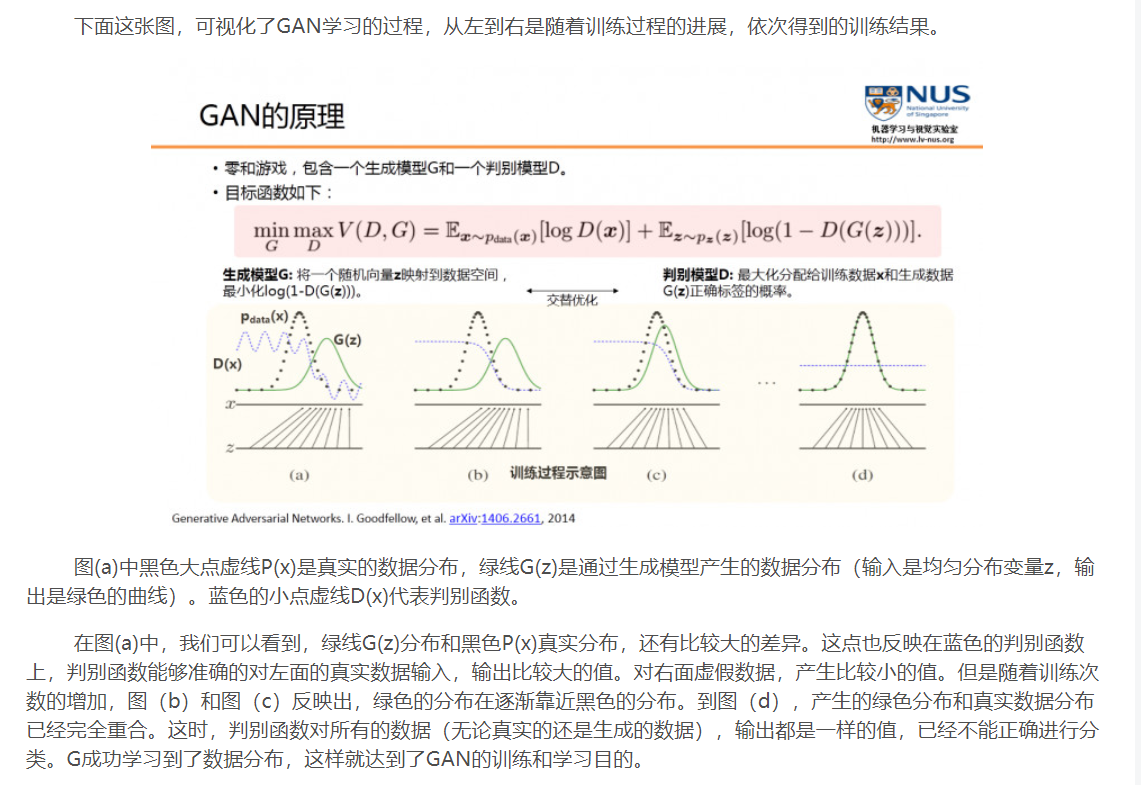






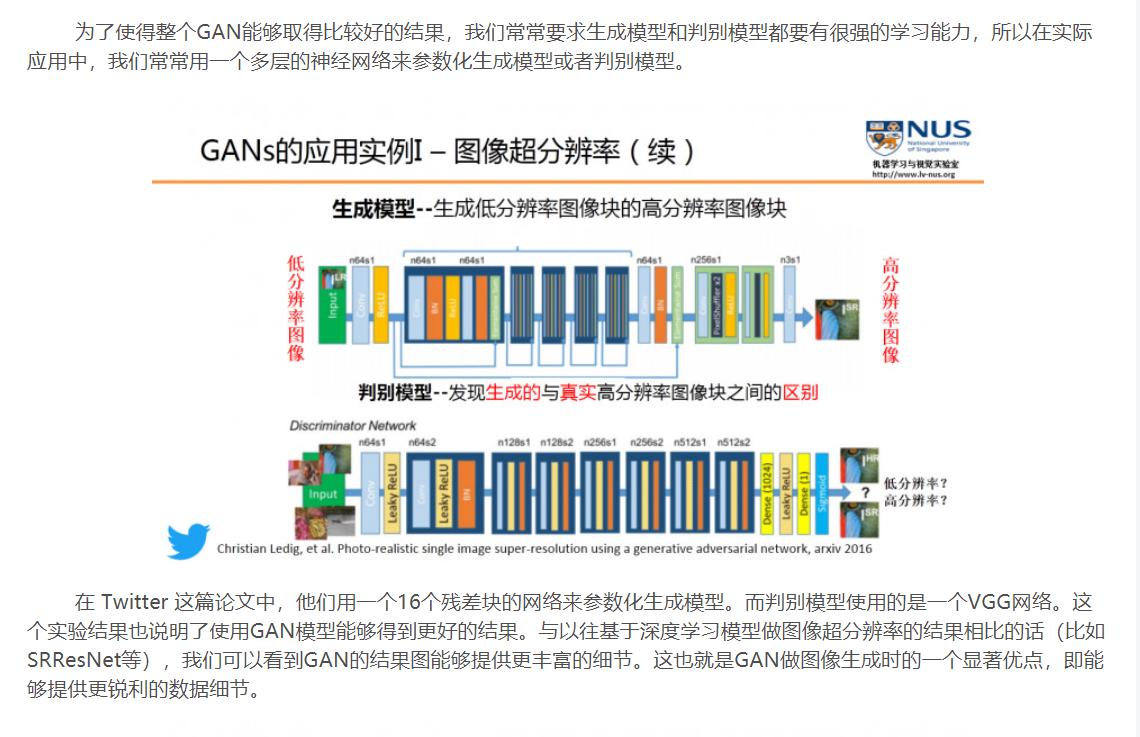
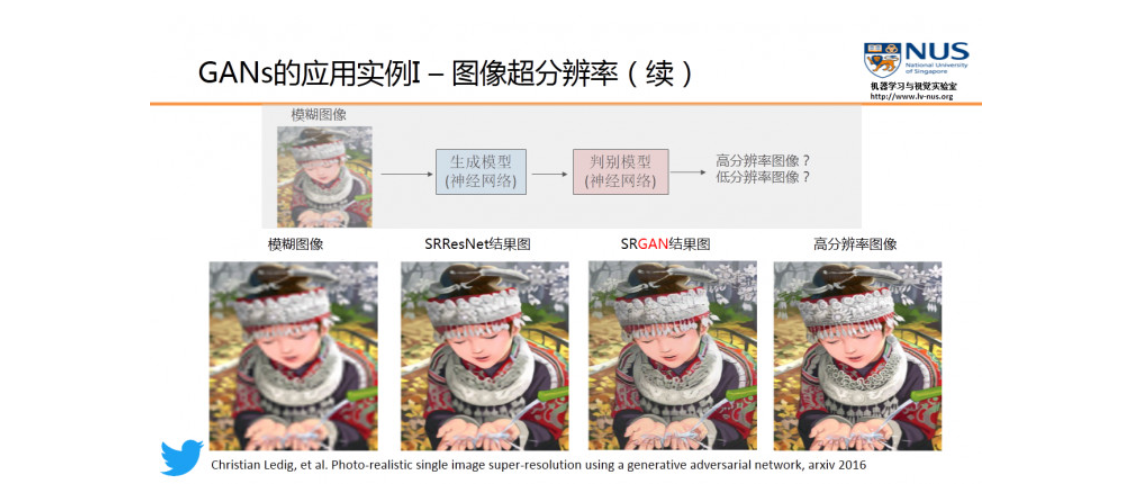




class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
"""
nn.Sequential的定义来看,输入要么是orderdict,要么是一系列的模型,
遇到list,必须用*号进行转化,否则会报错 TypeError: list is not a Module subclass
形参——单个星号代表这个位置接收任意多个非关键字参数,转化成元组方式。
实参——如果*号加在了是实参上,代表的是将输入迭代器拆成一个个元素。
"""
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
os.makedirs("https://raw.githubusercontent.com/LoveNingBo/LoveNingBo.github.io/master/https://raw.githubusercontent.com/LoveNingBo/LoveNingBo.github.io/master/data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(datasets.MNIST("https://raw.githubusercontent.com/LoveNingBo/LoveNingBo.github.io/master/https://raw.githubusercontent.com/LoveNingBo/LoveNingBo.github.io/master/data/mnist",train=True),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)