前言
ESIM,简称 "Enhanced LSTM for Natural Language Inference".
顾名思义,一种专为自然语言推断而生的加强版 LSTM.
ESIM 能比其他短文本分类算法牛逼主要在于两点:
-
1.精细的设计序列式的推断结构. -
2.考虑局部推断和全局推断.
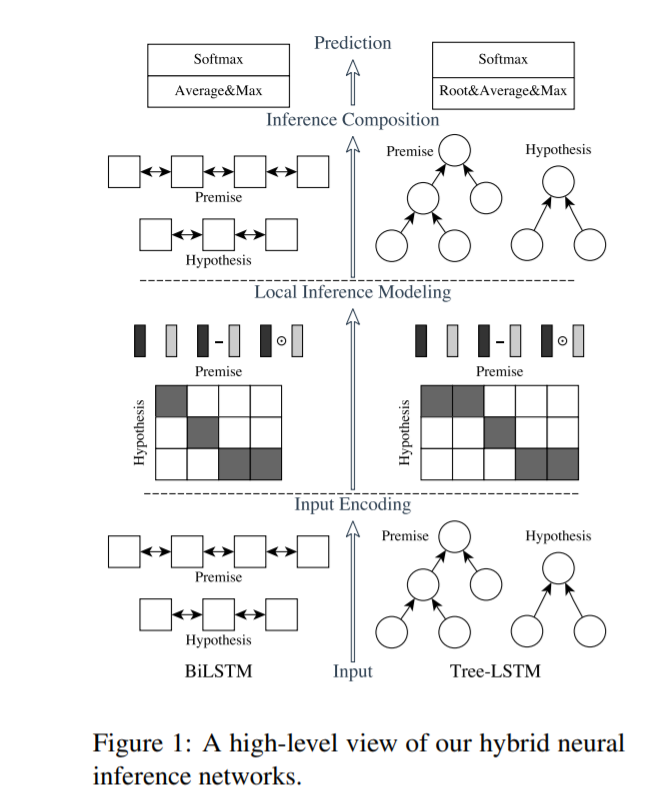
1.模型结构
ESIM的论文中,作者提出了两种结构,如下图所示,左边是自然语言理解模型ESIM,右边是基于语法树结构的HIM. 本文也主要讲解ESIM的结构,如果对HIM感兴趣的话可以阅读原论文。
##
ESIM一共包含四部分:Input Encoding、Local Inference Modeling、 Inference Composition、Prediction,接下来会分别对这四部分进行讲解。
##

def forward(self, *input):
# batch_size * seq_len
sent1, sent2 = input[0], input[1]
mask1, mask2 = sent1.eq(0), sent2.eq(0)
# embeds: batch_size * seq_len => batch_size * seq_len * embeds_dim
x1 = self.bn_embeds(self.embeds(sent1).transpose(1, 2).contiguous()).transpose(1, 2)
x2 = self.bn_embeds(self.embeds(sent2).transpose(1, 2).contiguous()).transpose(1, 2)
# batch_size * seq_len * embeds_dim => batch_size * seq_len * hidden_size
o1, _ = self.lstm1(x1)
o2, _ = self.lstm1(x2)
##

def soft_align_attention(self, x1, x2, mask1, mask2):
'''
x1: batch_size * seq_len * hidden_size
x2: batch_size * seq_len * hidden_size
'''
# attention: batch_size * seq_len * seq_len
attention = torch.matmul(x1, x2.transpose(1, 2))
mask1 = mask1.float().masked_fill_(mask1, float('-inf'))
mask2 = mask2.float().masked_fill_(mask2, float('-inf'))
# weight: batch_size * seq_len * seq_len
weight1 = F.softmax(attention + mask2.unsqueeze(1), dim=-1)
x1_align = torch.matmul(weight1, x2)
weight2 = F.softmax(attention.transpose(1, 2) + mask1.unsqueeze(1), dim=-1)
x2_align = torch.matmul(weight2, x1)
# x_align: batch_size * seq_len * hidden_size
return x1_align, x2_align
def submul(self, x1, x2):
mul = x1 * x2
sub = x1 - x2
return torch.cat([sub, mul], -1)
def forward(self, *input):
···
# Attention
# output: batch_size * seq_len * hidden_size
q1_align, q2_align = self.soft_align_attention(o1, o2, mask1, mask2)
# Enhancement of local inference information
# batch_size * seq_len * (8 * hidden_size)
q1_combined = torch.cat([o1, q1_align, self.submul(o1, q1_align)], -1)
q2_combined = torch.cat([o2, q2_align, self.submul(o2, q2_align)], -1)
...
##

def apply_multiple(self, x):
# input: batch_size * seq_len * (2 * hidden_size)
p1 = F.avg_pool1d(x.transpose(1, 2), x.size(1)).squeeze(-1)
p2 = F.max_pool1d(x.transpose(1, 2), x.size(1)).squeeze(-1)
# output: batch_size * (4 * hidden_size)
return torch.cat([p1, p2], 1)
def forward(self, *input):
...
# inference composition
# batch_size * seq_len * (2 * hidden_size)
q1_compose, _ = self.lstm2(q1_combined)
q2_compose, _ = self.lstm2(q2_combined)
# Aggregate
# input: batch_size * seq_len * (2 * hidden_size)
# output: batch_size * (4 * hidden_size)
q1_rep = self.apply_multiple(q1_compose)
q2_rep = self.apply_multiple(q2_compose)
# Classifier
x = torch.cat([q1_rep, q2_rep], -1)
sim = self.fc(x)
return sim
##
完整代码:
from torch import nn
import torch
import torch.nn.functional as F
class ESIM(nn.Module):
def __init__(self, args):
super(ESIM, self).__init__()
self.args = args
self.dropout = 0.5
self.hidden_size = args.hidden_size
self.embeds_dim = args.embeds_dim
num_word = 20000
self.embeds = nn.Embedding(num_word, self.embeds_dim)
self.bn_embeds = nn.BatchNorm1d(self.embeds_dim)
self.lstm1 = nn.LSTM(self.embeds_dim, self.hidden_size, batch_first=True, bidirectional=True)
self.lstm2 = nn.LSTM(self.hidden_size*8, self.hidden_size, batch_first=True, bidirectional=True)
self.fc = nn.Sequential(
nn.BatchNorm1d(self.hidden_size * 8),
nn.Linear(self.hidden_size * 8, args.linear_size),
nn.ELU(inplace=True),
nn.BatchNorm1d(args.linear_size),
nn.Dropout(self.dropout),
nn.Linear(args.linear_size, args.linear_size),
nn.ELU(inplace=True),
nn.BatchNorm1d(args.linear_size),
nn.Dropout(self.dropout),
nn.Linear(args.linear_size, 2),
nn.Softmax(dim=-1)
)
def soft_attention_align(self, x1, x2, mask1, mask2):
'''
x1: batch_size * seq_len * dim
x2: batch_size * seq_len * dim
'''
# attention: batch_size * seq_len * seq_len
attention = torch.matmul(x1, x2.transpose(1, 2))
mask1 = mask1.float().masked_fill_(mask1, float('-inf'))
mask2 = mask2.float().masked_fill_(mask2, float('-inf'))
# weight: batch_size * seq_len * seq_len
weight1 = F.softmax(attention + mask2.unsqueeze(1), dim=-1)
x1_align = torch.matmul(weight1, x2)
weight2 = F.softmax(attention.transpose(1, 2) + mask1.unsqueeze(1), dim=-1)
x2_align = torch.matmul(weight2, x1)
# x_align: batch_size * seq_len * hidden_size
return x1_align, x2_align
def submul(self, x1, x2):
mul = x1 * x2
sub = x1 - x2
return torch.cat([sub, mul], -1)
def apply_multiple(self, x):
# input: batch_size * seq_len * (2 * hidden_size)
p1 = F.avg_pool1d(x.transpose(1, 2), x.size(1)).squeeze(-1)
p2 = F.max_pool1d(x.transpose(1, 2), x.size(1)).squeeze(-1)
# output: batch_size * (4 * hidden_size)
return torch.cat([p1, p2], 1)
def forward(self, *input):
# batch_size * seq_len
sent1, sent2 = input[0], input[1]
mask1, mask2 = sent1.eq(0), sent2.eq(0)
# embeds: batch_size * seq_len => batch_size * seq_len * dim
x1 = self.bn_embeds(self.embeds(sent1).transpose(1, 2).contiguous()).transpose(1, 2)
x2 = self.bn_embeds(self.embeds(sent2).transpose(1, 2).contiguous()).transpose(1, 2)
# batch_size * seq_len * dim => batch_size * seq_len * hidden_size
o1, _ = self.lstm1(x1)
o2, _ = self.lstm1(x2)
# Attention
# batch_size * seq_len * hidden_size
q1_align, q2_align = self.soft_attention_align(o1, o2, mask1, mask2)
# Compose
# batch_size * seq_len * (8 * hidden_size)
q1_combined = torch.cat([o1, q1_align, self.submul(o1, q1_align)], -1)
q2_combined = torch.cat([o2, q2_align, self.submul(o2, q2_align)], -1)
# batch_size * seq_len * (2 * hidden_size)
q1_compose, _ = self.lstm2(q1_combined)
q2_compose, _ = self.lstm2(q2_combined)
# Aggregate
# input: batch_size * seq_len * (2 * hidden_size)
# output: batch_size * (4 * hidden_size)
q1_rep = self.apply_multiple(q1_compose)
q2_rep = self.apply_multiple(q2_compose)
# Classifier
x = torch.cat([q1_rep, q2_rep], -1)
similarity = self.fc(x)
return similarity